Getting back to nature: tree decomposition
I stumbled upon this topic when it came up as part of a proof in a paper. This is probably baby stuff to anyone who’s taken a graph theory class, but I haven’t and it was interesting, so here are my loose notes on it.
Tasty tree-ts
Let’s say we have an undirected graph $G = (V, E)$, defined by its vertices $V$ and edges $E$. I think I have a good intuitive sense of what a “tree” is, but what is it formally?
A tree just means that $G$ is connected and acyclic.
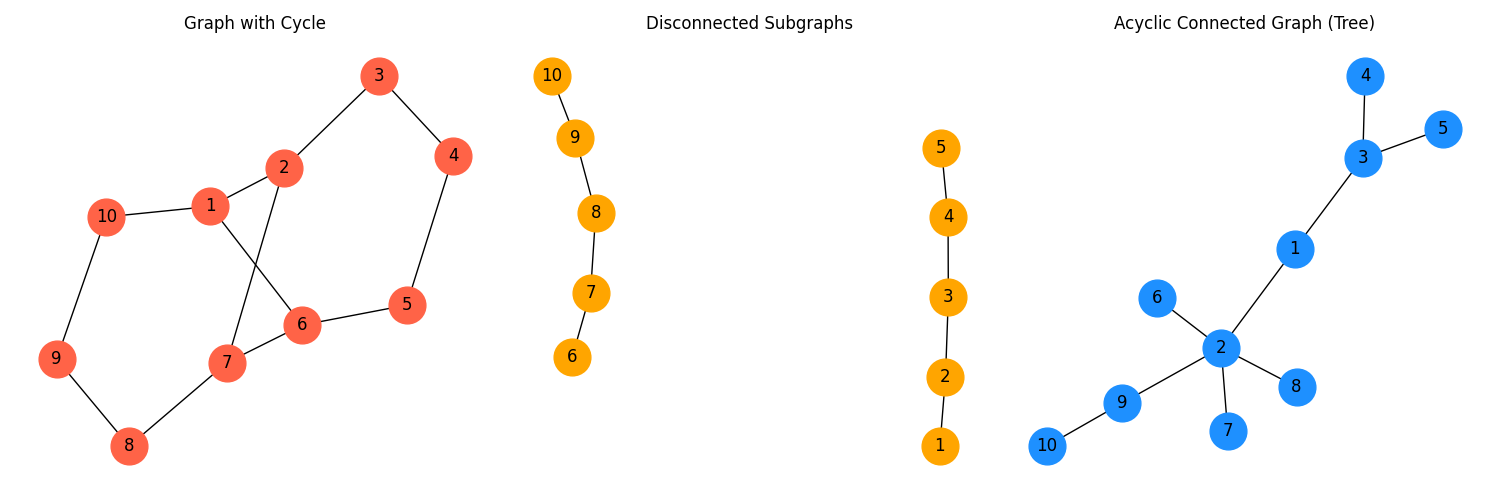
Intuitively: it’s a tree if there’s a single path from any vertex to any other vertex. Above, red fails because there are multiple paths between any pair, and orange fails because you can’t get from 4 to 7.
Return to nature - tree decomposition
Tree decomposition takes a graph $G = (V, E)$ (which generally is not a tree) and produces a related graph $T$ that is a tree.
To do this, we’ll choose $n$ subsets (often called “bags”) of the vertices: $X_i \subset V$. We’ll then treat these bags as nodes in a new tree $T$ (we say “node” to distinguish it from the vertices of $G$). We also have to define edges between these nodes to define $T$.
To be a tree decomposition (TD), the subsets $X_i$ and edges between have to follow a few rules:
- every original vertex $v \in V$ has to be in at least one bag; i.e., all the vertices have to be the union of the bags: $V = \cup_i X_i$
- for an edge $(v, w) \in E$, there has to be at least one bag $X_i$ that contains both $v$ and $w$
- lastly, the bags $X_i$ that contain a given vertex $v$ form a connected subset of $T$, that itself is a tree
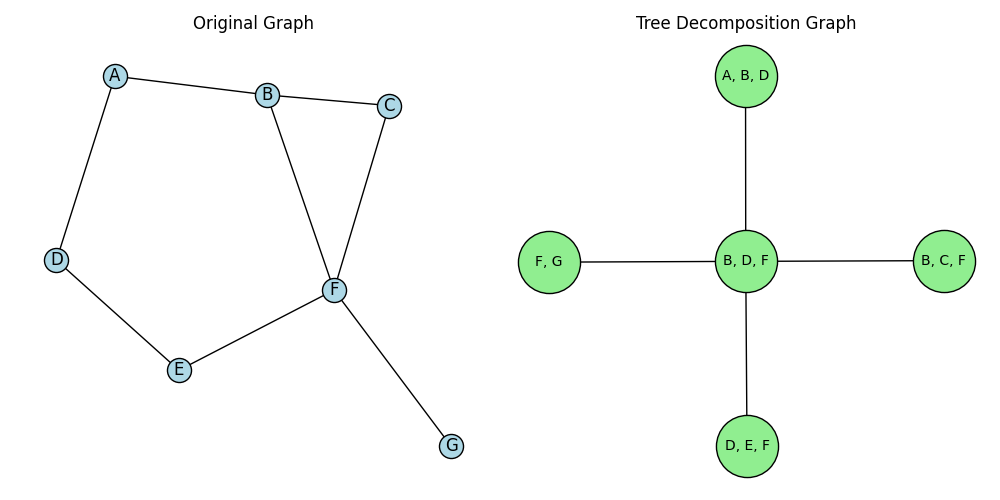
Here’s an example from wiki, where I’ve more explicitly drawn a few steps in defining the tree:
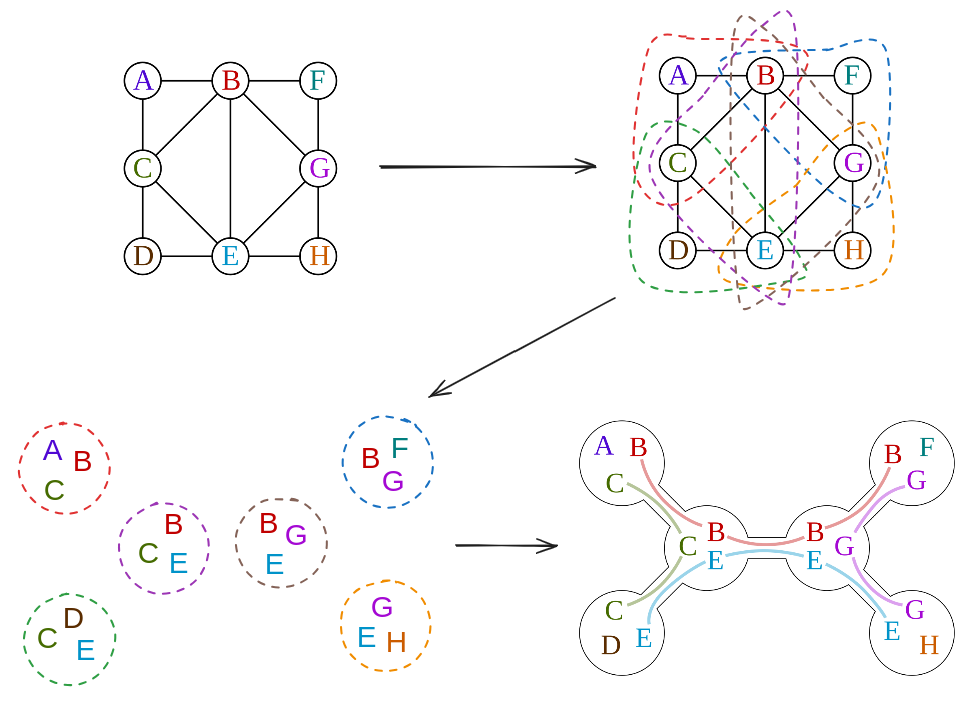
I’ve outlined the bags from their example in dashed boundaries with different colors in the original graph, and then drawn their corresponding bags/nodes in the new graph $T$. You can see that each of the rules is obeyed:
- the subsets definitely contain all the nodes from $G$ (they cover all the vertices in the 2nd stage)
- every edge in $G$ is within one of the dashed $X_i$ subset nodes (in the 3rd stage)
- when we look at the set of $X_i$ that contain a given vertex in the last panel, they’re each a tree (connected, and no cycles)
A natural question is whether there’s only this one decomposition for $G$, or there can be more. It’s pretty easy to see that we could instead do:
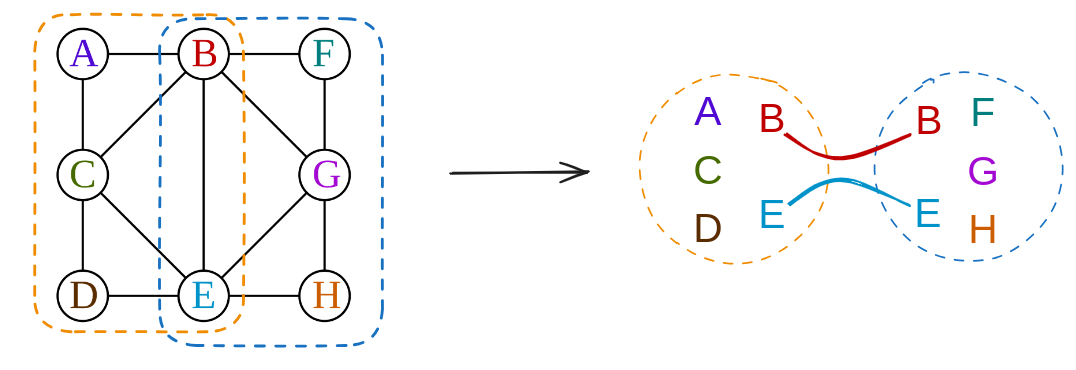
or even this one:
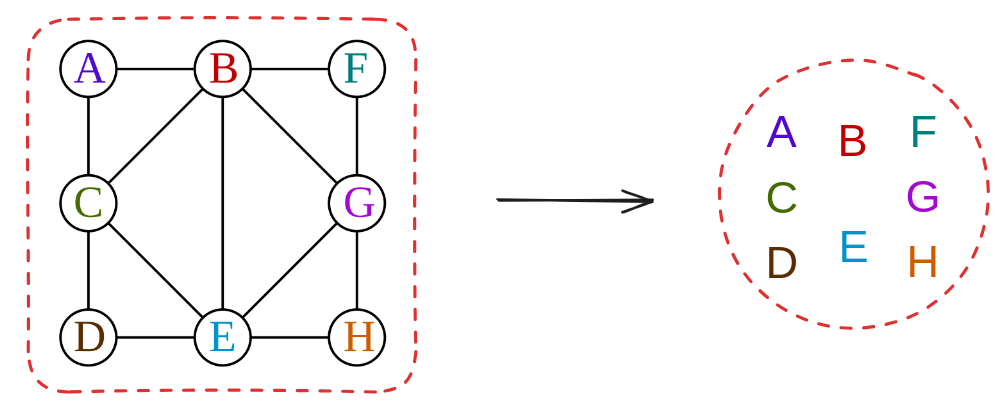
Check the rules! It’s valid.
In fact, you might notice that while the others depended on the specific structure of the example graph $G$ to various extents, this one doesn’t depend on it at all, since we literally just circled the whole graph in one bag. For this reason it’s the “trivial” tree decomposition.
What’s different about these different TD’s, then? This leads nicely to the next part.
Treewidth
First, the “width” of a TD is the size of the largest subset $X_i$, minus one. So for the examples above:
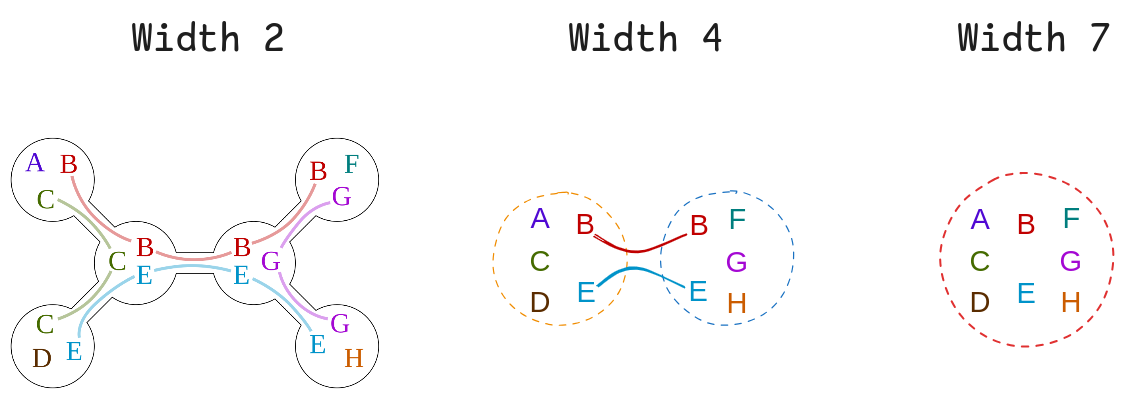
and like we said, it sure seems like as the width gets bigger, the TD seems to be less specific to the specific $G$ we started from. Another way to see this is to start from a TD and see which original $G$ could give rise to it. We know that the width 7 (trivial) TD could come from literally any $G$ with those nodes, because we can always choose the whole graph to be the single bag.
For the width 4 TD, we know that there are some graphs that can’t give that TD, so it’s a little more restricted. For example, since rule 2 says that if there’s an edge $(v, w) \in E$, there must be some $X_i$ that contains both $v$ and $w$, we know that pairs $(A, F)$ or $(C, G)$, etc, can’t have edges between them in $G$. But we can’t say whether there’s an edge $(A, C)$ or $(E, H)$ – there might be, but doesn’t have to be. You can see a few of the different $G$ that could have this TD:
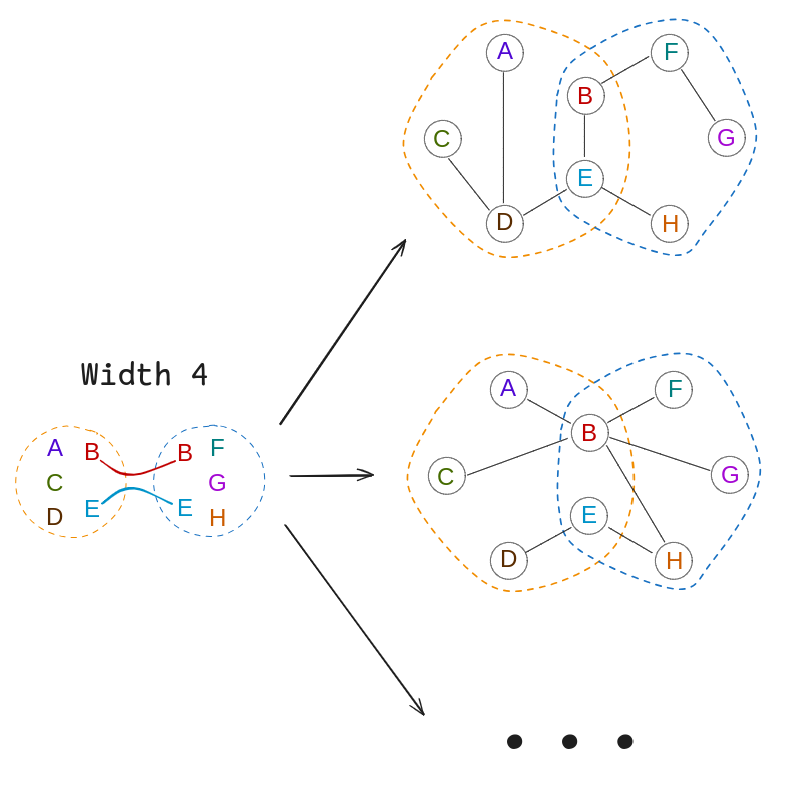
So there are fewer $G$ that could give rise to the width 4 TD than for the trivial one. If we tried it with the width 2 TD, you’d find that it’s even more constrained and there are even fewer.
The next natural question is, if the trivial TD is the extreme in one direction, what’s the extreme in the other direction? How small can the width of a TD get?
This is basically what the treewidth (TW) of a graph $G$ is: the smallest width of any TD we can make for the tree. I.e., we saw above that you can make many TD’s with different widths from the same graph, so you consider all of them and then choose the one with the smallest width.
The intuition wikipedia gives for its meaning is “how far the graph is from being a tree”, where graphs that actually are trees have a TW of 1, and a fully connected graph would have a TW of the number of vertices minus one.
Since the TD in the wiki example already has a width of 2, and it’s not a tree (since it has cycles), and the smallest TW any graph can have is 1 if it is a tree, we know that the TD they gave for it is indeed the best that can be done and its TW actually is 2.
I also found it helpful to look at what exactly limits the TW; i.e., what stops a given graph from having the smallest possible TD of 1. Remember that the width of a given TD is the size of its largest set $X_i$ minus one. Therefore, if we want to find a TD of a graph with width 1, it means that all the sets $X_i$ we define must be of size at most 2.
We can try with the wiki example we’ve been looking at above. In fact, we can even see the idea if we take the subgraph of only the three vertices in the upper left corner:
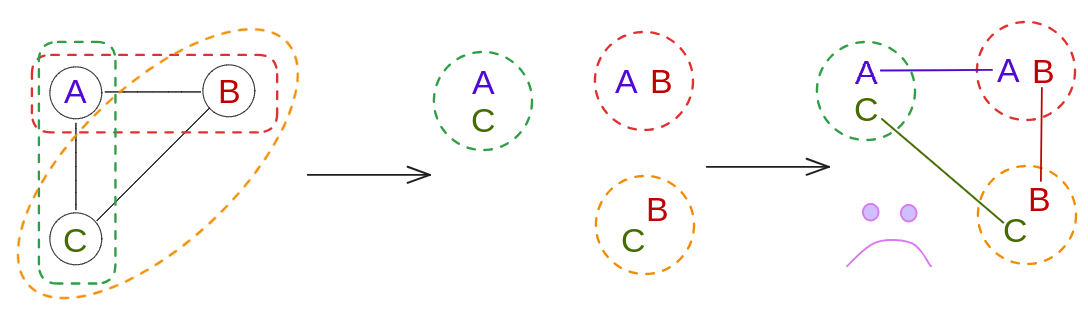
We don’t have much choice in how we choose the $X_i$: to satisfy rule two, we have to put each pair of vertices of an edge in some $X_i$, and since we want the largest $X_i$ to be at most 2, it can’t have all three vertices. So the $X_i$ are ${A, C}, {A, B}, {B, C}$ as pictured above. Then, we have to draw the edges in $T$. To satisfy rule three, for a given vertex $v \in V$, for any pair of bags $X_i, X_j$ that both contain $v$, there must be a unique path between $X_i$ and $X_j$, and every $X_k$ in between them also has to contain $v$. In this case, each of $A, B, C$ are only in two nodes, so we just have to connect them as pictured above.
However, after drawing the required edges, we can see that $T$ isn’t… a tree, and therefore not a TD. To actually get a valid TD, we’ll have to have all three vertices in the same node $X_i$, giving a width of 2, which is what the wiki TD had too. If we tried to enforce the tree-ness of $T$ while keeping at most two vertices in the same bag, we’d find that we’d have to break a different rule (probably the 2nd).
Missing the forest for the tree widths
Lastly, I want to wrap up with a little computational exercise. I want to attempt to make a little script that will find the best TW for given graphs it can. I haven’t looked up anything about standard ways of doing this, so I’m just gonna wing it and see how what I get compares to standard approaches. All I know is that I was seeing “NP-“ prefixes a lot in a skim of the TW wiki article, so it’s probably a hard problem that you only ever get approximate solutions for 😬
I’ll talk through my thought process and intuition while I wing it. Let’s call the original graph $G$ and the TD graph $T$. I have a few intuitions from the previous sections:
A) any tree can be formed by starting with a single vertex, and then “splitting” off an edge from that vertex, that connects to a new vertex. Repeating this splitting step can lead to any tree from a single vertex, because it’ll never create cycles.
B) we know that the trivial TD is a single bag/node with all vertices from $G$, and the ideal TD is one with more nodes, that each have smaller numbers of vertices.
So these make me want to start with a big ol’ trivial single bag TD, and then apply a splitting step where I split a source node, creating a new node with some of the vertices, and removing some subset of vertices in the source node. Since we only care about the largest node size, repeating that process until some stopping condition should give TDs of decreasing width. My one question/worry with this approach is that I don’t know how much “path dependency” there will be in the splitting choices. I.e., could some earlier splitting choice put us in a state where we would never find the optimal solution?
Anyway, I need a bit more intuition for the splitting step. What does it mean to split?
We know that for an edge $e_i$ in $G$, there must be some node in $T$ that has both of $e_i$’s vertices. So we sometimes need vertices in the same node, but we saw from the different width examples before that the TD’s that have too-large widths seem to vertices that don’t need to be together in the same (with the trivial TD being the extreme version).
So here’s my initial guess at the process:
1) we choose a node $X_j$ to split 2) we choose a vertex $v_i \in X_j$, to try and split it out into a new node 3) we take $v_i$ and its neighbors in $G$ that are in $X_j$, and put them in a new node $X_k$, leaving the remainder in $\tilde X_j = X_j \setminus X_k$ 4) we then iterate through the $v_k \in X_k$. If one of them has a connection to any of the remaining in $\tilde X_j$, its edge needs to be maintained, so we mark it as needing to be added back to $\tilde X_j$. Similarly, if a $v_k \in X_k$ already had an outgoing edge to another node, it would have to maintain that continuity (rule 3 above), so we’d need to add it back to $\tilde X_j$ as well. 5) we then add all the needed ones back to $\tilde X_j$, and rename it back to $X_j$.
Trying it with this simple 4-cycle:
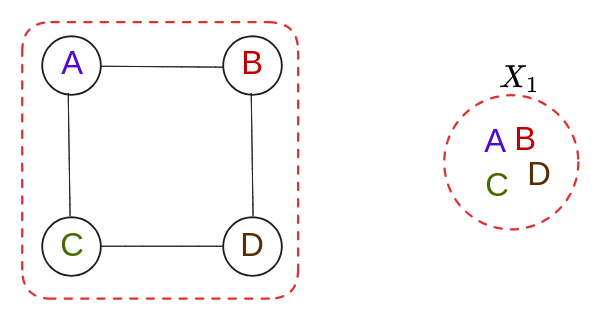
Select A to try and split off. It’s connected to B and C so we split them off with it, into $X_2$. But then, B and C both have connections to $D$, so we mark them as needing to be added back:
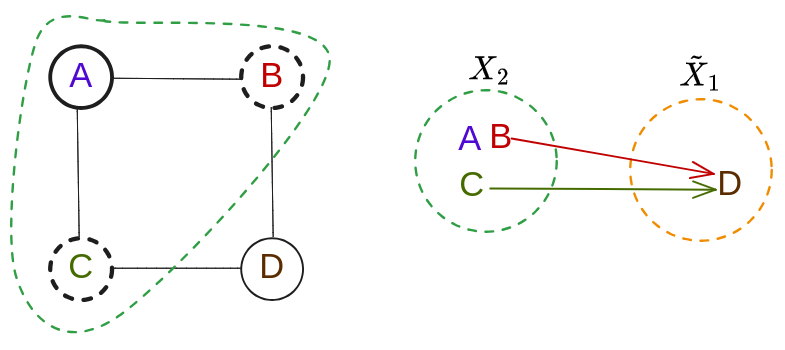
finally, add B and C back to $\tilde X_1$ and call it $X_1$:
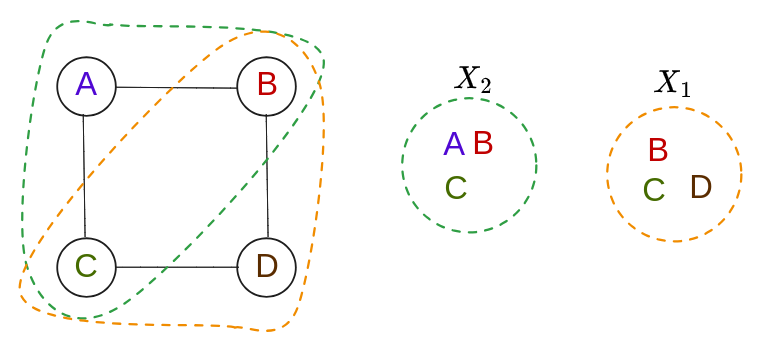
In this case we know it’s done, since this TD has width of 2 and we know $G$ isn’t a tree.
To try it with a slightly more complex example (not gonna annotate it, just show the first few steps):
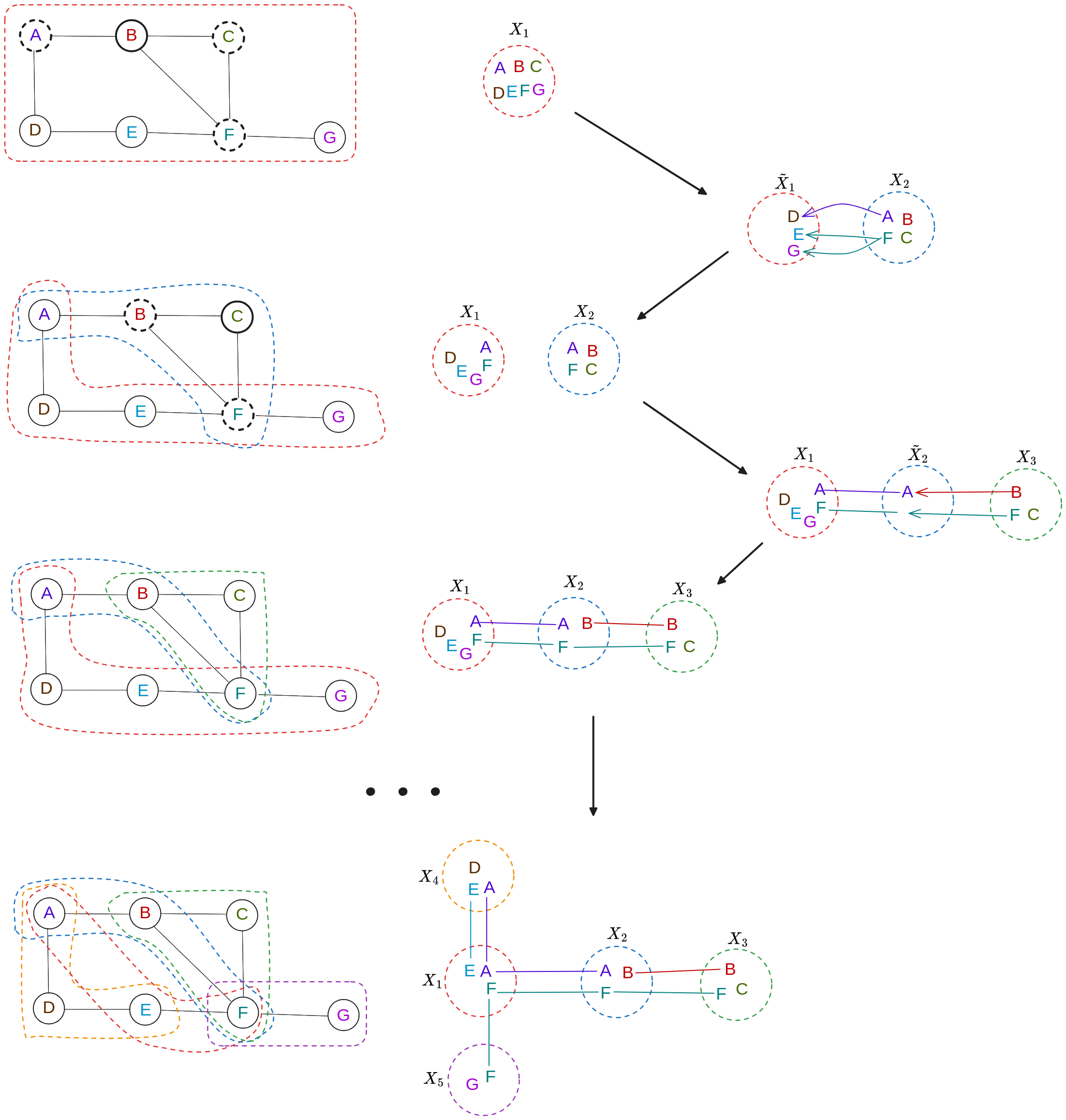
Cool! We can say this is done for the same reason as the previous one: it has width 2, and it’s not a tree.
But this makes me realize that we’ll also have to decide on the stopping condition in general. I think we can start with a “splittable vertices” list that’s all vertices, and keep removing from it until it’s empty. I think we can say that if any vertices are in more than one node, we can stop considering it as a splittable vertex, because it’ll necessarily have to bring all its neighbors in the current node with it, and we wouldn’t gain anything. The last condition, I think, would be where we have a vertex like G above, that’s only in a single node, but its neighbors set is exactly the set of other vertices in its node.
So… I think that should work? Let’s try coding it up. Here’s the solution in finds for the second one:
It’s actually a different solution than I found above, but I… think it’s right? In terms of node sizes, it also has 2, 3, 3, 3, 3. Yeah, I wrote a quick little method to check the rules, and it does.
Since LLMs are magic and cheap, I made it also print out the intermediate steps like above:
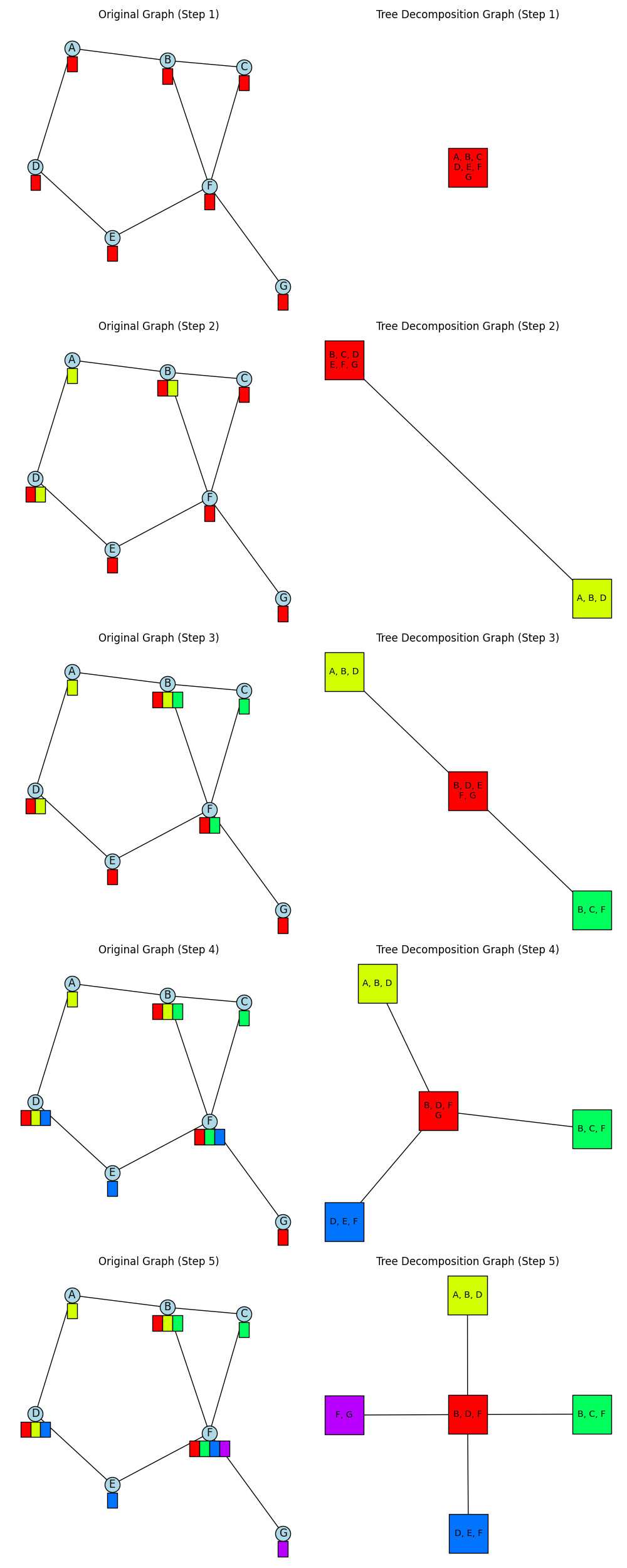
Hmm, okay, trouble in paradise. I was thinking that this seemed awfully easy given how hard a problem it probably is. So I went to run it on a bigger one, and noticed that the TW it was getting was… a lot bigger than what networkx said it is.
Here it is, showing the history too. Mine finds 7, it finds 4:
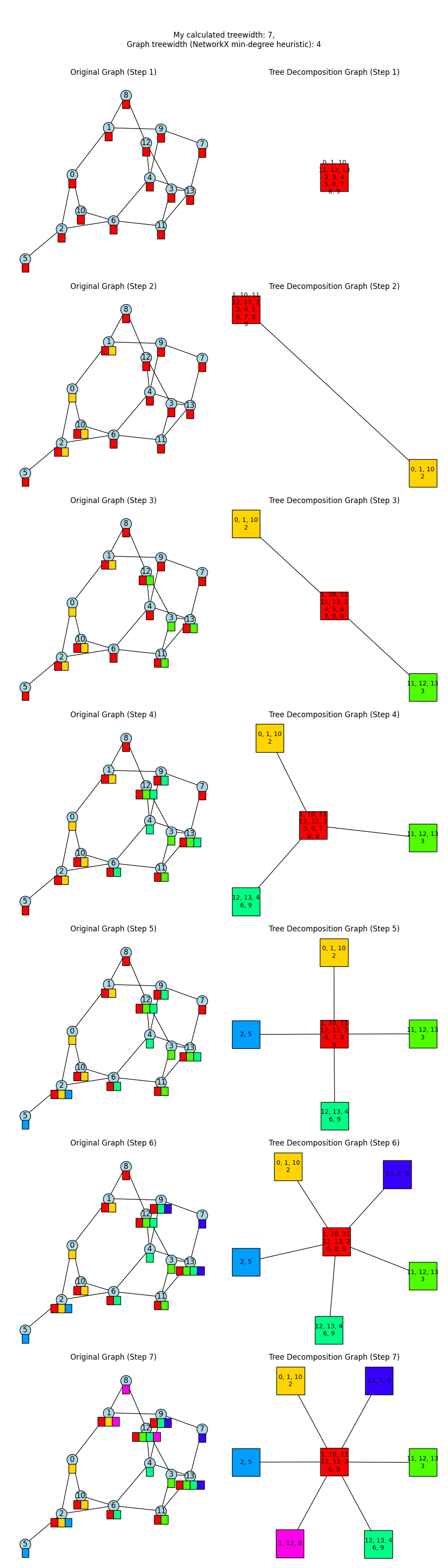
I have a hypothesis. I’ve noticed that in both the examples I had my script run on, it seems to produce a kind of “hub and spokes” shape. For example, in my last example above where I did it by hand, my hand solution had some TD nodes a distance of 2 from the “hub” (the {A, E, F} node), while the one it found had all nodes a distance of 1 from the {B, D, F} “hub”.
My guess is that my script is just going through the remaining splittable vertices in an (arbitrary) index order, while in my example above I chose to split the node on vertex B, which happens to have a bunch of connections. I’m thinking that if I don’t do this, it kind of greedily splits on vertices that are valid, but ultimately don’t create TD’s with small widths. I can’t say why this is at the moment, but it seems intuitively plausible…
Okay, now I made it first try to split the largest node at each iteration, and inside each node, try to split on the vertex with the most number of neighbors. This gives, for my earlier example:
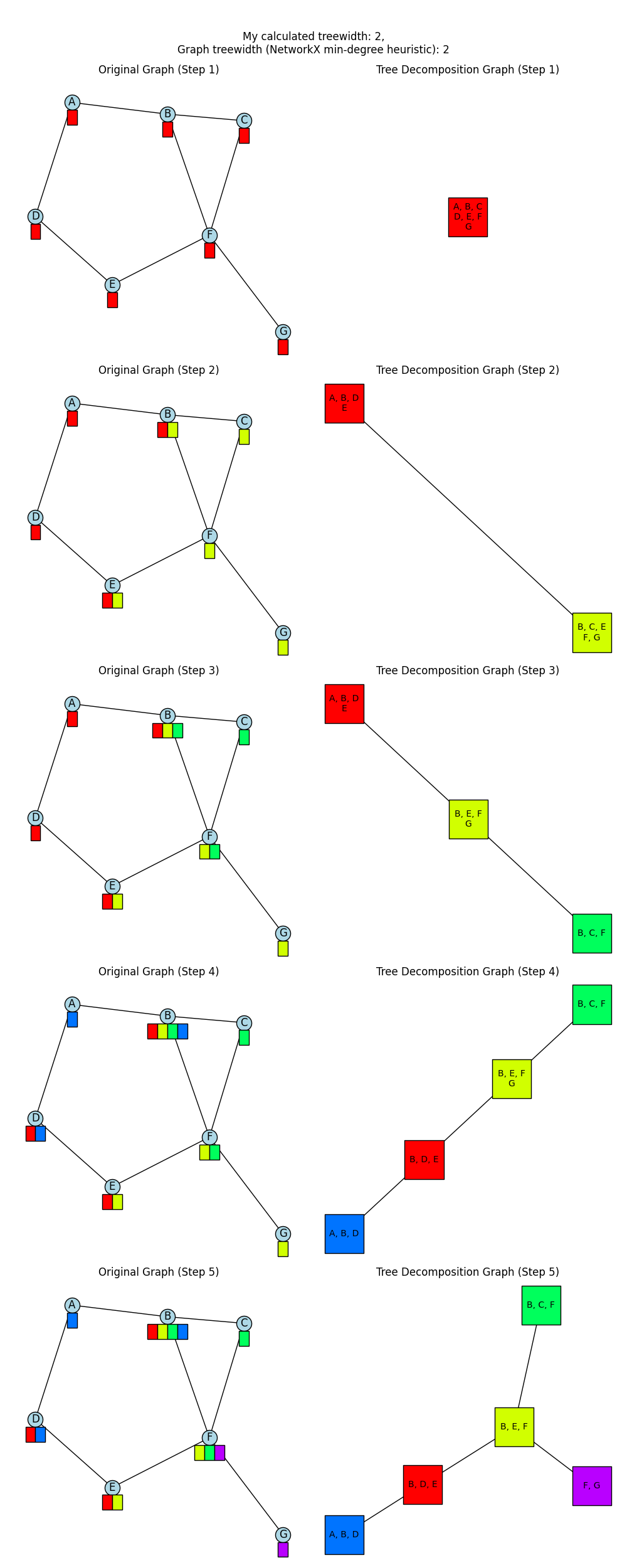
which is promising! Since it has the form that mine had. And for the larger example above:
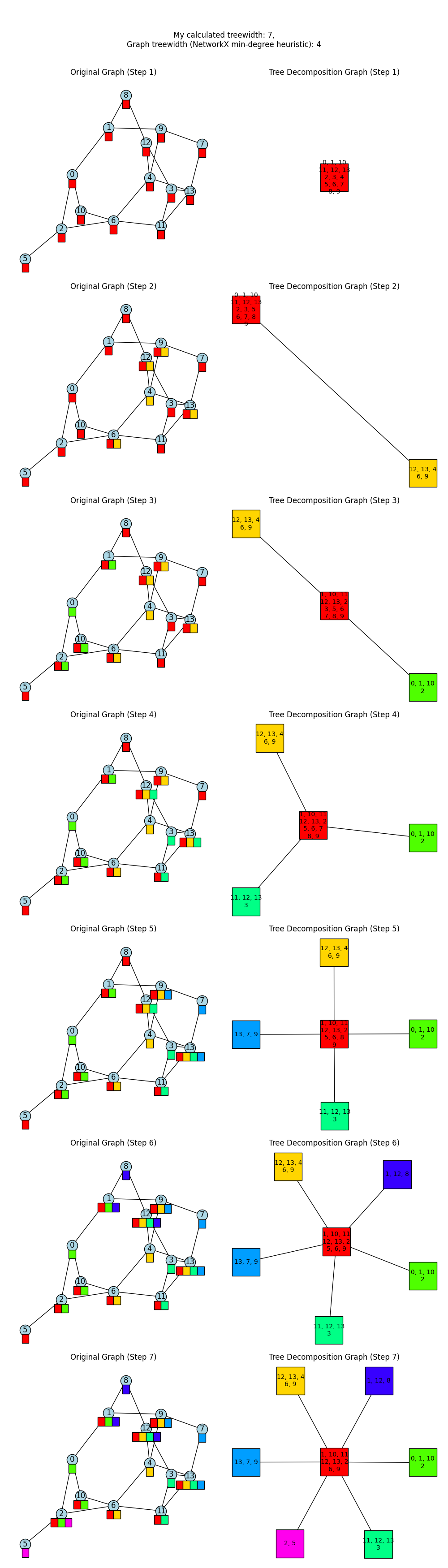
…womp womp. Same result. It looks like I prob overgeneralized here, and my intuition wasn’t right, since this gives basically the same solution. Now that I’m looking at it, I’m realizing that maybe I don’t want to split only single vertices, I should be splitting whole sections of the graph. And, it’s making me realize that I’m dimly aware of the existence of “min cut” algorithms… so I wouldn’t be surprised if the better idea involves those. I could see it being good to split the TD nodes into the biggest blobs possible at each step.
Okay, I think in the interest of trying to not always finish posts, I’m gonna leave it here today, and someday revisit it. Fun was had. Things were learned.