Standard Operating Procedur...al generation
I’ve been wanting to try out some procedural generation for a while now. Something about being able to produce complex landscapes/designs/etc from pretty simple rules fascinates me.
It’s the type of thing that’s ideal for vibe coding – the math and ideas behind most of the methods are pretty simple, but implementing them graphically (by hand) would be a real PITA for me. And, it seems like they’re common enough that the LLMs often one-shot them, and then I can just tweak them to make them look a bit better.
Today I mostly wanna get the flavor of a few of the common methods. They’re only new to me, but maybe you’ll like looking at the pretty shapes and colors. I’m doing it in three.js since it’ll just run client side in the browser and let me easily make it 3D. GPT tends to be really capable with JS and three.js too.
Today let’s just look at a few really basic ones. If you just wanna see them without reading below, click the links below!
I’m gonna keep it real loose today, so the “notes” below will be very disjointed.
Diamond-square algorithm
From wikipedia:
The diamond-square algorithm begins with a two-dimensional square array of width and height 2n + 1. The four corner points of the array must first be set to initial values. The diamond and square steps are then performed alternately until all array values have been set.
- The diamond step: For each square in the array, set the midpoint of that square to be the average of the four corner points plus a random value.
- The square step: For each diamond in the array, set the midpoint of that diamond to be the average of the four corner points plus a random value.
Each random value is multiplied by a scaling multiplier, which decreases each iteration by a factor of 2−h, where h is a value between 0.0 and 1.0 (lower values produce rougher terrain).
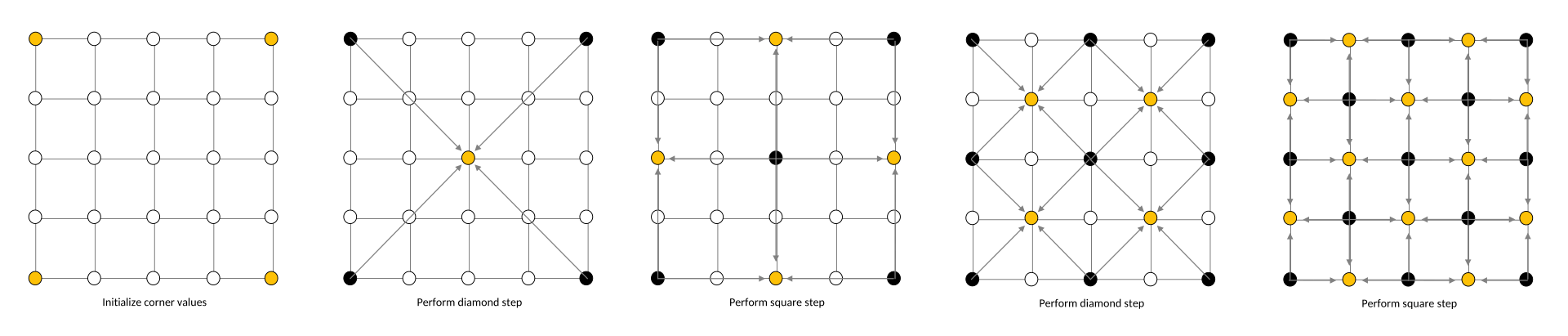
Pretty straightforward. It’s basically a repeating loop of interpolating and perturbing, and increasing resolution scales.
The AI one-shots it:

Perlin noise
Perlin noise: a little more complicated but still easy. It’s an example of a class of noise methods called Gradient noise.
Create grid, add random unit vector at each grid intersection:
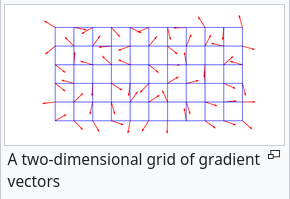
Any given point will lie in one of those grid cells, and in $n$ dims, have $2^n$ corners (with a unit vector at each of them).
For one of the corners, you can take the dot product between A) the vector from the corner to the point (“offset vector”), and B) the unit vector at that corner. Here it shows each point’s dot prod with the closest corner:
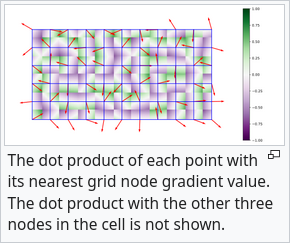
but there are $2^n$ corners for each point. To combine them, they interpolate using a function like “smoothstep”:
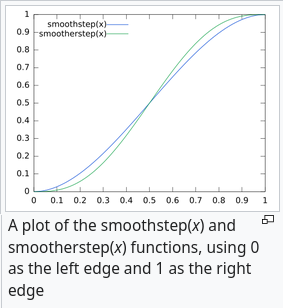
it both interpolates, but also has zero derivative at the end points. Because the dot product between the offset and unit vector depends on the offset vector, and the mag of the offset goes to zero as a given point approaches a corner, and the interpolation becomes entirely the closest dot product, you can see that the interpolated value is zero at all grid intersections:
Again, the AI one shots it:

Ok, made it so it’ll add higher frequencies together with diminishing amplitudes, so we can get fractal noise:
$m=1$:

$m=2$:

$m=4$:

$m=8$:

Honestly, really looks like landscape in some ways:

Simplex noise
Simplex: follows from Perlin, but a bit more complicated. One of the main goals of it is to fix the lousy scaling (with growing dimension) that Perlin has. If you look above at Perlin, if you’re creating noise in $n$ dimensions, then there are $O(2^n)$ dot products to do per candidate point. That’s because for a point within a square/cube/hypercube/etc, there are $2^n$ corners.
(The Simplex page actually says Perlin needs $O(n2^n)$, so I’m guessing they’re including the $n$ multiplies for each $n$-dim vector dot product in there.)
Anyway. Simplex is a very similar idea in terms of creating the noise via a sum of dot products between the offset vector (from the candidate point) and a gradient vector at a cell’s corner. But, they do a clever transformation so that the “cell” is formed from only $n + 1$ corners (the corners of a triangle/tetrahedron/etc).
I made this little script to picture it for a candidate point:
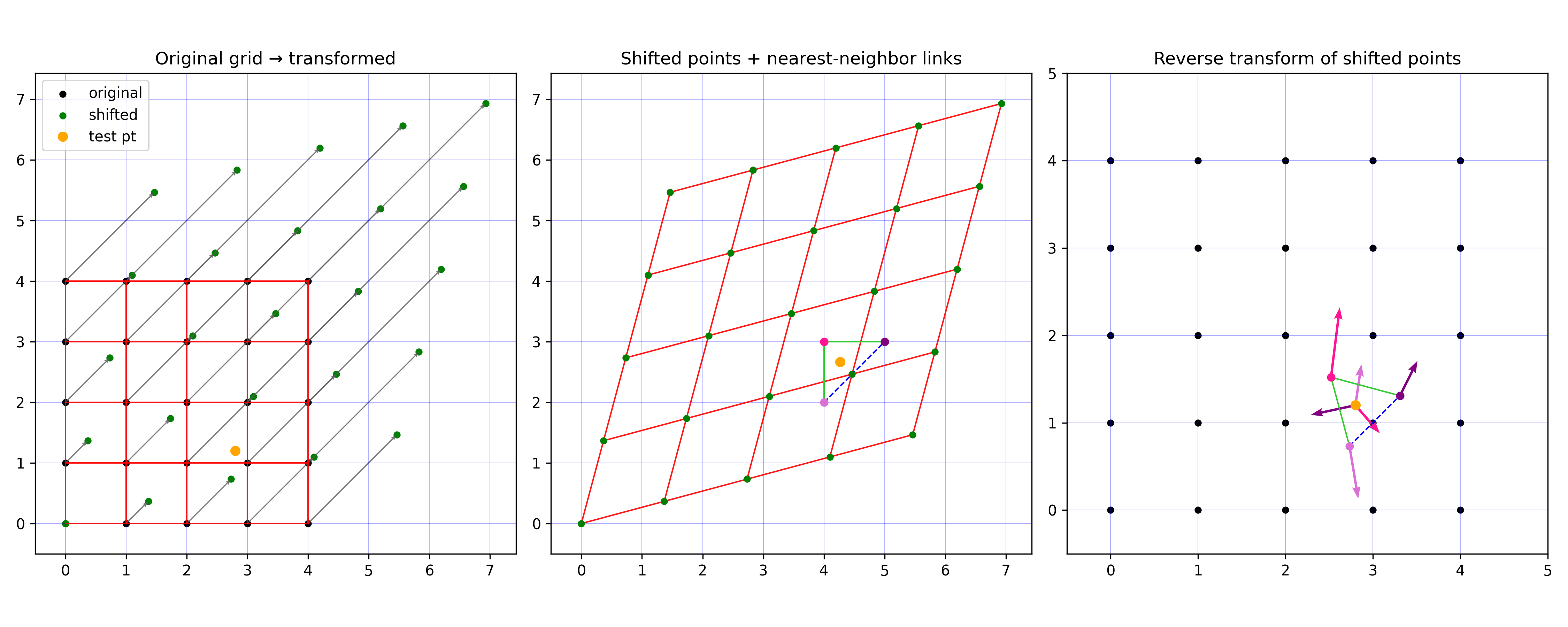
aaaaand again the LLM kills it:

Worley / Voronoi noise
Worley noise. Or Voronoi noise, but I like how the word “Worley” sounds more.
Super simple. Basically just the distance to the closest feature point. There are lots of variations though. If $F_i$ is the distance to the $i$th nearest, you can also do:
- simplest: $F_1$
- inverted: $1 - F_1$
- $F_2 - F_1$
- use squared/manhattan distance instead of euclidean
- etc
The AI did it really easily, but I iterated a few times to get some features working, like having the cells move / change it to the raw cells view, etc:


Value noise
At first I thought the wiki article was too vague, but the method really is just stupidly simple. It’s exactly what wiki says, but more detailed:
- you define a lattice (similar to perlin/simplex)
- you sample values at each of the lattice points
- you interpolate between these lattice point values to get the values at the spots in between
To get the values in between the lattice points, you can interp linearly, or smoothly. People often also add value noise at different octaves, with decreasing amplitudes.
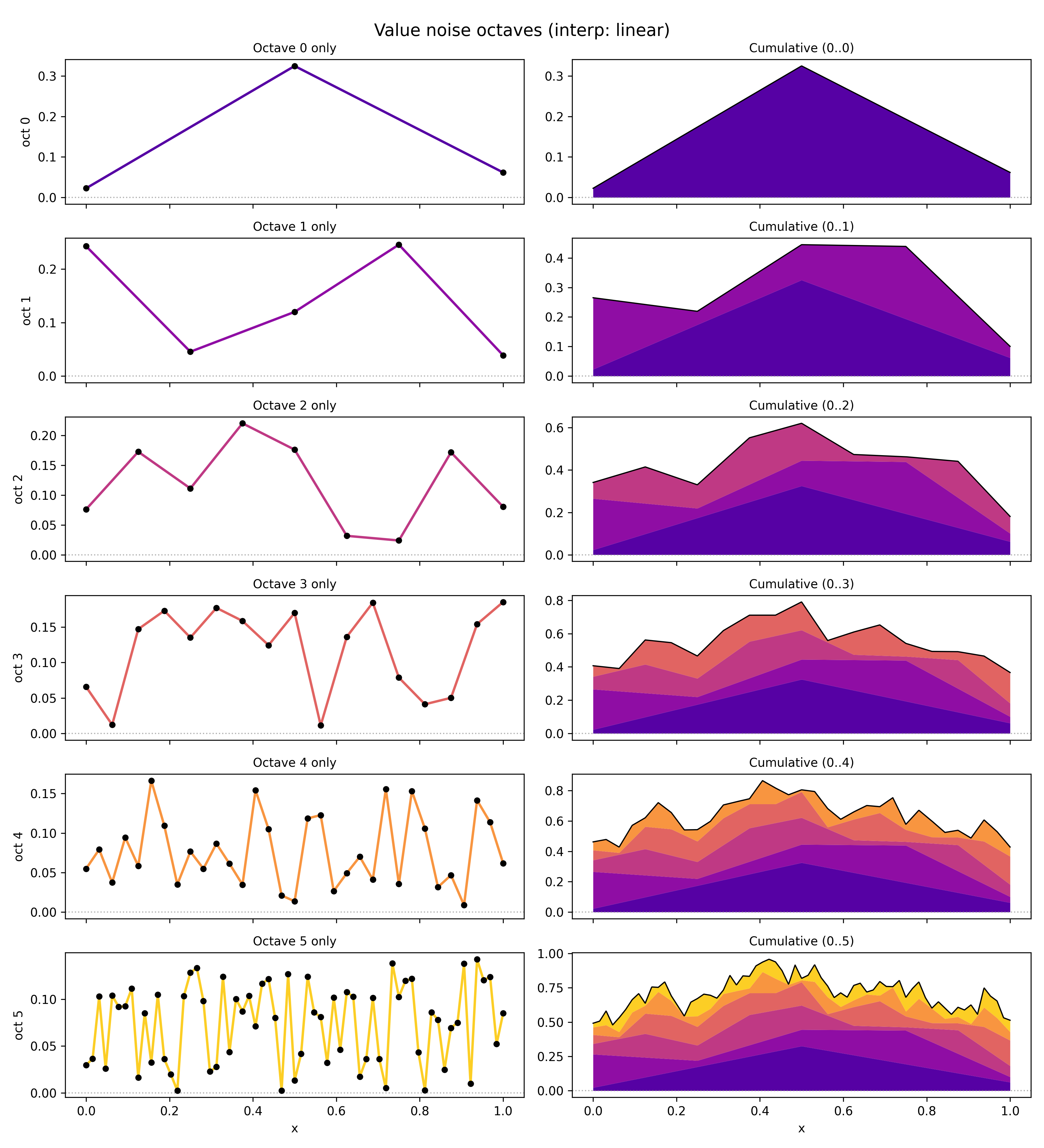
I made a handy little script to visualize it exactly, showing the lattice for each octave, its value noise (left column), and the cumulative noise up to that octave (right column).
Here’s linear interpolation:
and here’s cubic:
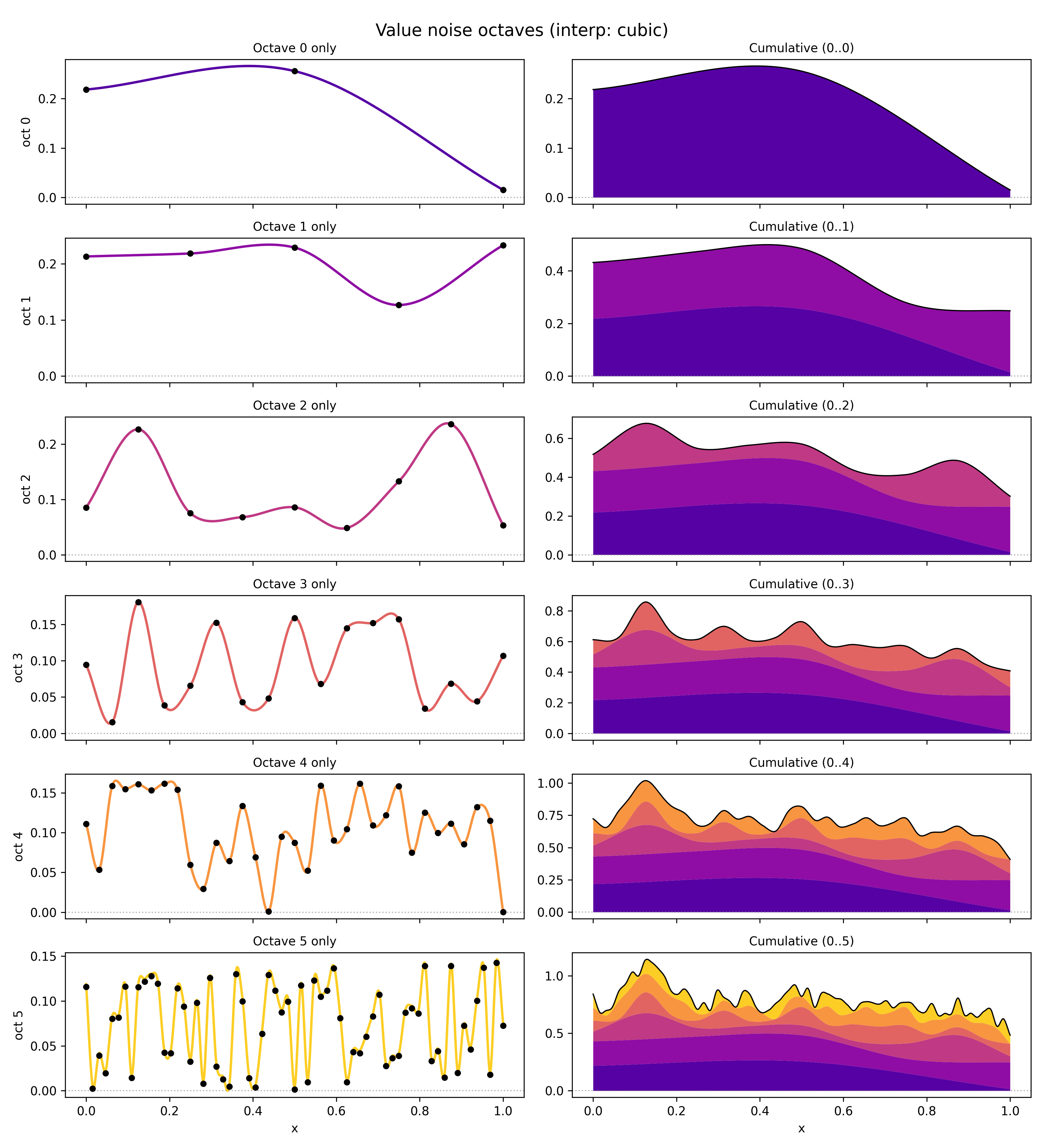
Here, I’ve sampled each octave’s lattice $y$ values from $[0, 1]$ uniformly (before scaling with the amplitude). For the amplitude, I used $1/(i_\text{octave} + 1)$ (I think this technically makes it “pink noise”?. I think $1 / 2^i_\text{octave}$ may be more common, but mine looked better here. I’ve also added an offset to make sure the minimum value after interp is $\geq 0$ (cause the cubic can make it dip negative), so we can visualize it like so in the right column.
Here’s the three.js demo, which the AI totally nails again. For this one, I added a slider that lets you choose how many octaves it includes in the sum. However, the octaves (for a given refresh/seed) are precomputed, so it lets you see the effect of adding more or fewer octaves to the same one. Here is is at 2, 4, and 9 octaves:
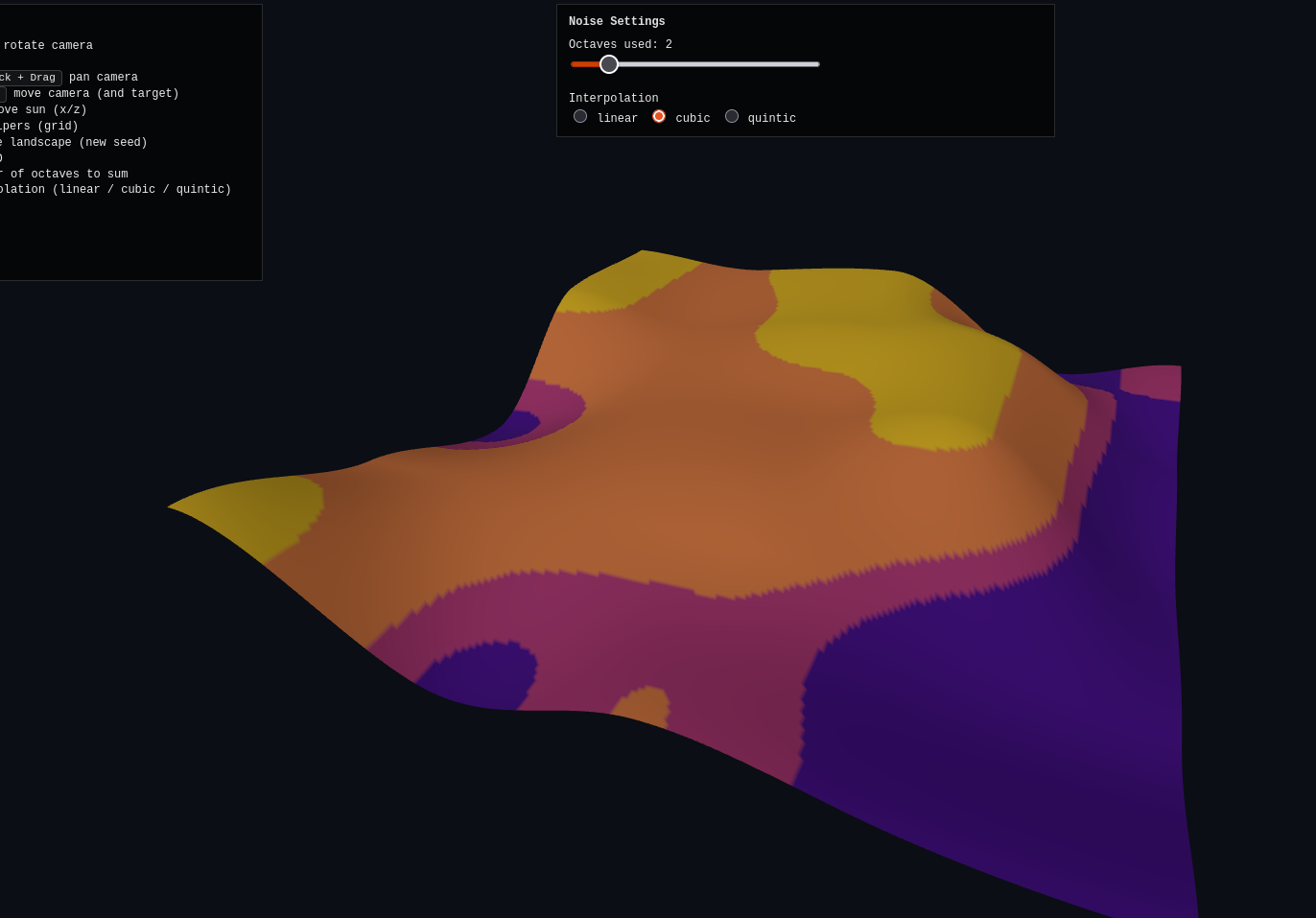
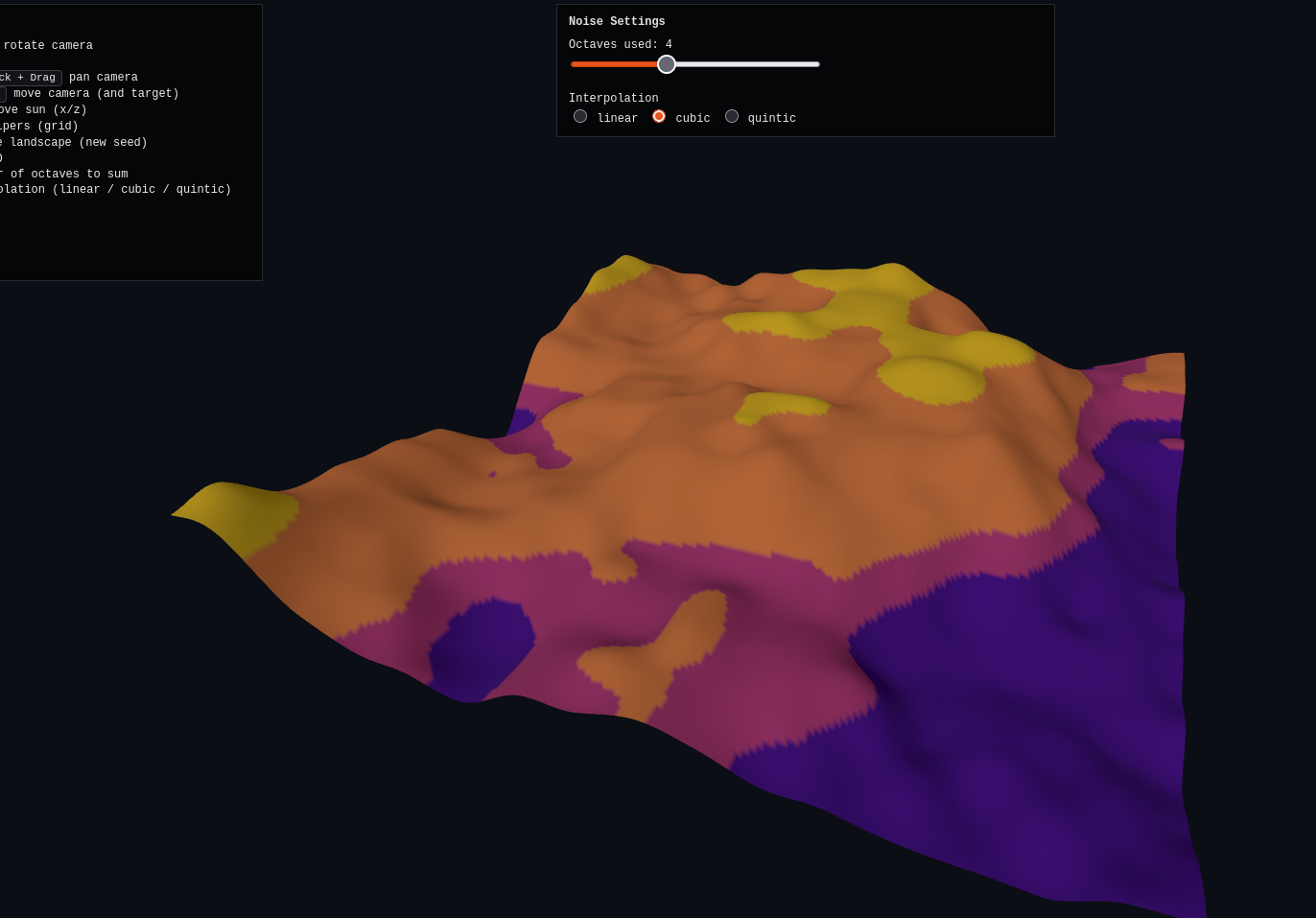
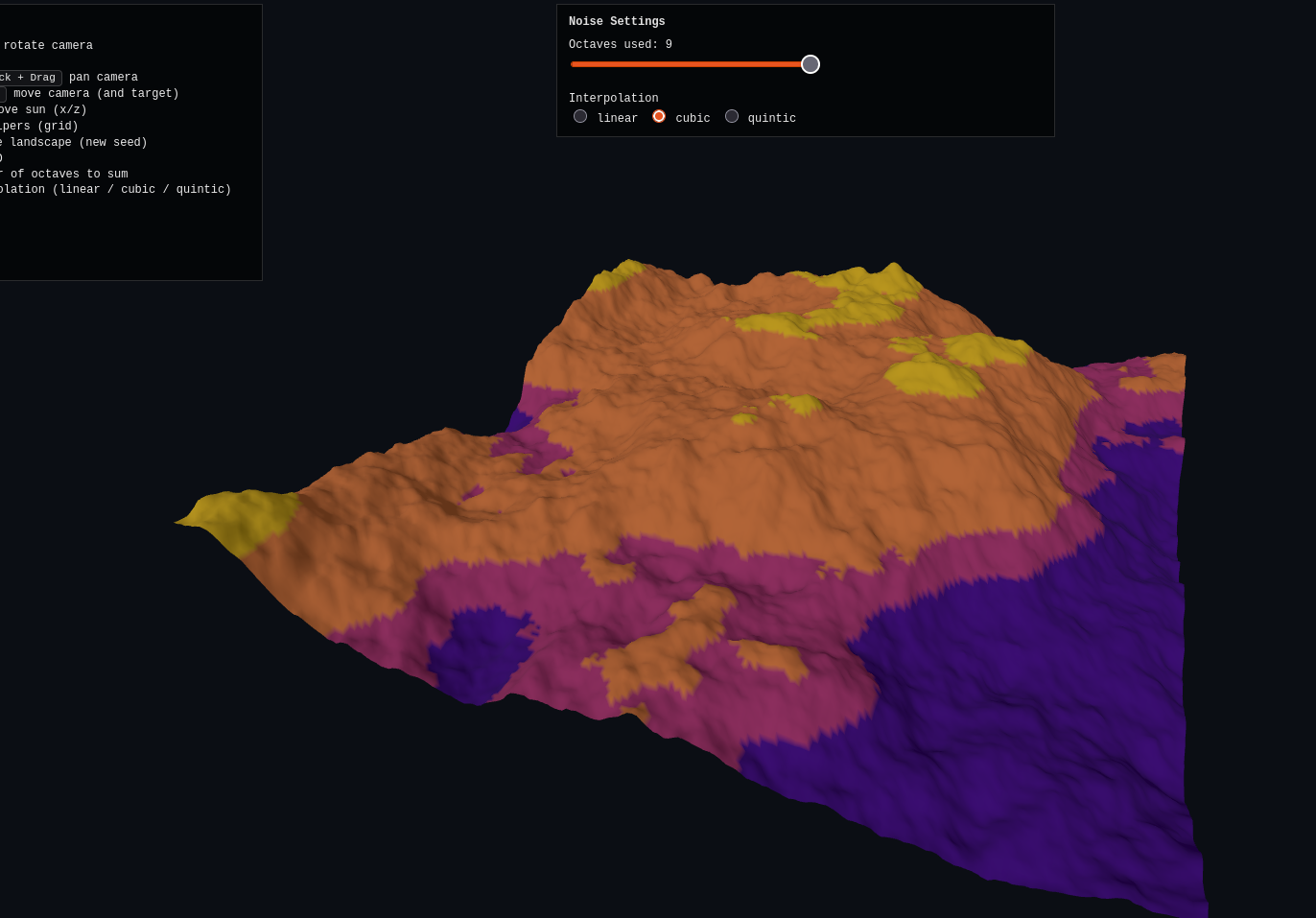
You can also change the interp, but it doesn’t seem to change as much here, because I think it’s dominated by simply the resolution of the noise sampling itself.
One last thing: I think the Diamond-square algo at the beginning would actually count as a value noise method, since it’s directly storing/combining noise values. However, it is a little different, with its recursive construction.
Closing thoughts/errata
Gradient vs value noise
Here’s something I don’t totally get. The wiki article stresses that:
[Value noise] is conceptually different from, and often confused with gradient noise, examples of which are Perlin noise and Simplex noise.
I mean… I see that we created value vs Perlin noise via different recipes. But, I don’t necessarily see why they’re necessarily conceptually different, since it feels like we’re just sampling and creating smooth curves from the sampled values in either cases.
GPT’s answer to this was:
value noise only controls values, perlin noise controls slopes. Perlin noise was invented specifically to fix visual artifacts in value noise.
I guess maybe the “conceptual” difference here is that VN directly chooses the values and then interpolates them, while gradient noise samples the gradients and effectively integrates them to turn them into values.
Why is this better? I don’t really know. Classic wisdom says that “differentiating removes info, integrating adds info”. So maybe gradient noise methods inherently “upscale” in a way that looks nicer?
Several times the stuff I quoted in this post mention stuff about fixing “visual artifacts” – I’m guessing that in actual practice, this is actually a bigger deal that I looked at today. I’m sure if you actually want to use procedural generation for a real purpose (and not just fun), there are a million edge cases or subtle undesirable patterns that can occur, and then the methods have to get really clever. So maybe, like they say, that’s something value noise doesn’t do that the gradient methods handle well (though I’d still like to learn why).
Next time
At this point I’m really just trying to get a sense of what’s out there, since eventually I’d like to experiment with almost procedural “worlds” containing all sorts of stuff. So I’m mostly trying to learn the “palette” or “toolchest” of options there are. However, even after what I learned from this post, it’s still fairly crude – I’m not sure when exactly someone would choose to use one method over the other. So that’ll take some more searching.
Today, the methods I looked at were mostly for generating “noise”, or more charitably, “patterns”. And those are certainly a really important part of proc gen, but there’s so much more. Next time I’ll look at some other methods that are more about “constructing” things, like plants or buildings.