Hey there! It's been a while. I've been working on lots of stuff, but here's a small thing I did recently.
My friends and I have a Slack we've now been using casually for a few years. You can download the entire logs of your Slack workspace, even if you use the free one (which will cut off the messages it shows you after 10,000 messages, I believe). So I wanted to do a few little projects with it.
One thing my friends and I were talking about was making bots that were crappy, funny imitations of us. So there would be a Declan-bot, Ben-bot, etc., that would talk like we do. Maybe we'll try that in the future, but after doing the thing in this post, I have a suspicion that the bots might be kind of indistinguishable without extreme tailoring (though I'd love if they weren't!).
So, what I wanted to do here was make a word cloud of each person's total corpus in Slack. It actually all came together pretty quick, mostly because I did it in a quick, hack-y way.
First, to get the Slack data, you have to be an administrator. You go to the menu, administration, workspace settings, import/export, export, and then choose the date range. The folder is pretty huge, several GB. You'll only get public data (not private messages), which makes sense. When you download it, it's organized by folders corresponding to the channels everything was in, and in each of those, .json files for each day.
json is fortunately super easy to use in python, since it basically gets read as a dictionary. I made a little program that goes through recursively and gets all the files, and then piles everything together into one huge json... dictionary? That lets me easily select everything from a single user, or channel, or other aspect.
Another little detail is that it doesn't label the users by our names (which you can change), it labels us by a unique identifier string, like U2189232 or something. So I had to make a little translation dictionary to go back and forth between names and IDs.
I decided to use this guy's great python word cloud generator to make the word clouds. It's even installable via pip3!
So, that's the basics. Import all the data into one big json database/dictionary thing, choose a user, translate to their ID, grab all the text with that ID, turn it into a big ol' list of words (with repeats), and then feed it into that word cloud generator. And it works! Here are a few:



But you'll immediately notice a few things. One is that there's some stuff we probably don't want there, like http and user tags (because if you say someone's name with the @, it just technically calls their ID and renders it as their name). Additionally, there are a ton of common words. It turns out that we like saying "yeah" and "one" a lot, so that tends to give rise to kind of lame word clouds.
This problem is actually a lot more interesting than you might think at first glance. I wanted to give the clouds a little more "personality". That is, there are a few unique words in each word cloud that, knowing my friends, I'm able to point out and say "yeah, Max plays Magic, so he probably does say 'deck' a lot", but there aren't many of those words. What I'd really like is if the top N words of each person's word cloud were pretty unique to them, but it turns out this is actually kind of tricky.
One thing I tried, that worked with some success, was taking the "megacorpus" from everyone's combined corpuses (corpi? or is it like octopuses?), taking the 400 most common words from that, removing them from each person's corpus, and then making them. This is definitely a slight improvement:
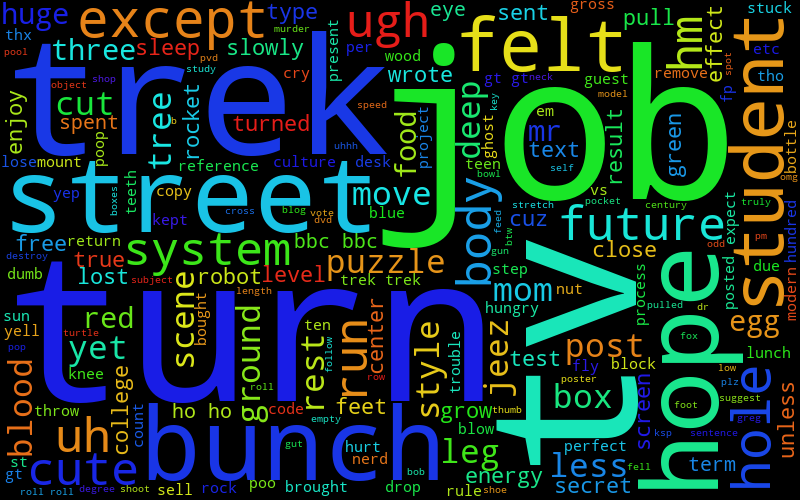

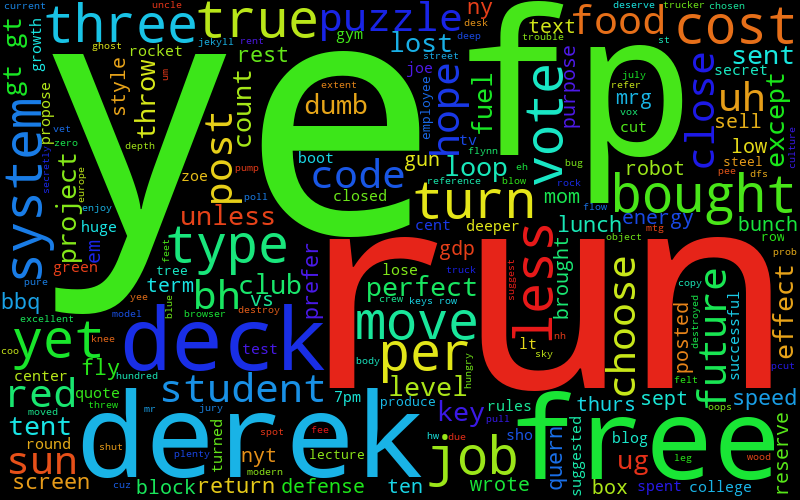
It's not great, though. For example, there could be a word that's used a ton by one or two users, and no one else, that might get removed. This would be a very "personal" word that I'd definitely want kept in their word cloud(s). I think it's also hard to know where the point is where you stop removing common, lame words and start removing interesting, personal words.
Here's what I'd ideally like: to make a list of the top N words, for each user, that are in the top N words of at most X other users I'm considering. So, if I'm making the top 10 lists for 8 of my friends, I might say that a "top 10" word can stay in a given list if 2 people have it in their top 10, but not if 3 do (then it's just too common).
How do you do this, though? The naive way I tried it was this. Get each user's corpus, sort by commonality (just for that corpus). So, you have a list with one occurrence for each word, sorted by decreasing use. Then, start with user 0. Start with their most common word (index 0 of that list), and check if it's in the top N of each other user. If it is, add to the tally of how many others share that word (that starts at 0 for each new word). If more users have that word in their top N than are allowed, remove that word from everyone's corpus. If you removed the word, you keep the index the same, but now it will be looking at a new word in the top N because the one it was just referring to just got removed. If the word didn't have to be removed, increase the index (so now it's looking at the next most common word in user 0's top N). When you get to index N of user 0, go to the next user and restart. Here's the relevant code for that:
for user in users:
print('\n\ngetting unique words for',user)
other_users = copy(users)
other_users.remove(user)
print('other users:',other_users)
index = 0
while index<=N_unique:
others_with_word = 0
cur_word = users_corpuses[user][index]
print('\ncur word is \'{}\''.format(cur_word))
for other_user in other_users:
if cur_word in users_corpuses[other_user][:N_unique]:
print('{} also has this word'.format(other_user))
others_with_word += 1
if others_with_word>allowed_others:
print('removing \'{}\' from all users'.format(cur_word))
for tempuser in users:
users_corpuses[tempuser].remove(cur_word)
else:
index += 1
print('\n\nTop {} unique words for {} at this point'.format(N_unique,user))
[print('{}. {}'.format(i,word)) for i,word in enumerate(users_corpuses[user][:N_unique])]
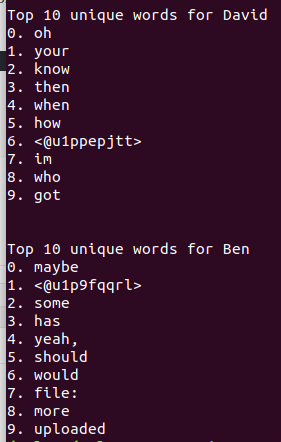
So, if you're smarter than me, you might see the flaw in this. Here are the top 10 for just David and Ben after running that:
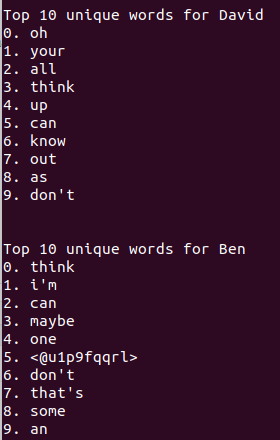
You might notice that they share "think", "can", and "don't". What's happening? Well, we can see by printing out David's corpus before it moves on to Ben's (as opposed to just at the end, like above):
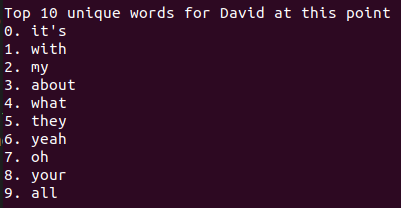
His top 3 at the end of the algorithm are his bottom 3 before Ben's gets calculated. This is what's happening. In David's top 10 calculation, when his list got to 'with', it checked the other users (just Ben in this case) to see if it was in their top 10's. It apparently wasn't, so it moved on. Then it found some word lower down in David's top 10 that was in Ben's top 10, and removed that from both of theirs. But each time a word gets knocked out of Ben's top 10, the list shifts up, introducing new words into Ben's top 10. After a few of these, 'with' appears in Ben's top 10, but David's has already checked for that. When David's is done, Ben's list does the same. It finds a few words that aren't in David's list, keeps them, but then finds (apparently) the top 7 words of David's top 10 (after only his search), which get removed, and likewise replaced with words that Ben's list has already checked.
So what can you do here? You could just do another round or several of checking, but I'm honestly not sure this would work (and would sure as hell be inelegant). That is, if Ben's check removed 7 of David's, and still had a bunch of overlaps, there's a good chance David's would then remove several of Ben's (if you repeated it), and I dunno how far down the rabbit hole you'd have to go.
Well, one solution that mostly works is this. It's a little brute-force-y, but simple to implement. If the problem is that words a user's list has already checked may appear in the other user's list as a result of removing later words, you can just make sure to check all the words again each time you remove a word. That is, last time, if you had checked words 0-4 of your top 10, and they weren't in other users lists, but you just removed word 5, it's possible one of words 0-4 just got introduced in another user's list in position 9, so you probably want to check your words 0-4 again. This is accomplished by just resetting the index (index = 0) each time a word is removed:
if others_with_word>allowed_others:
print('removing \'{}\' from all users'.format(cur_word))
for tempuser in users:
users_corpuses[tempuser].remove(cur_word)
index = 0
else:
index += 1
This is theoretically slow, but it's checking a few pretty short lists that it's not really a problem. Here they are now:
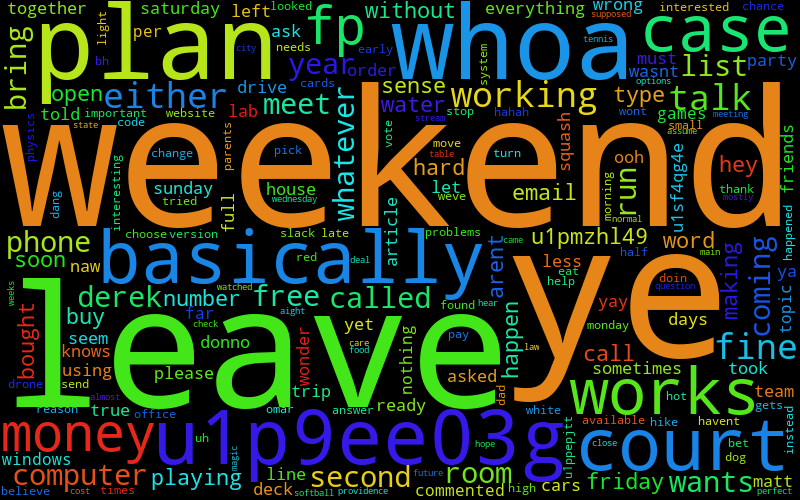
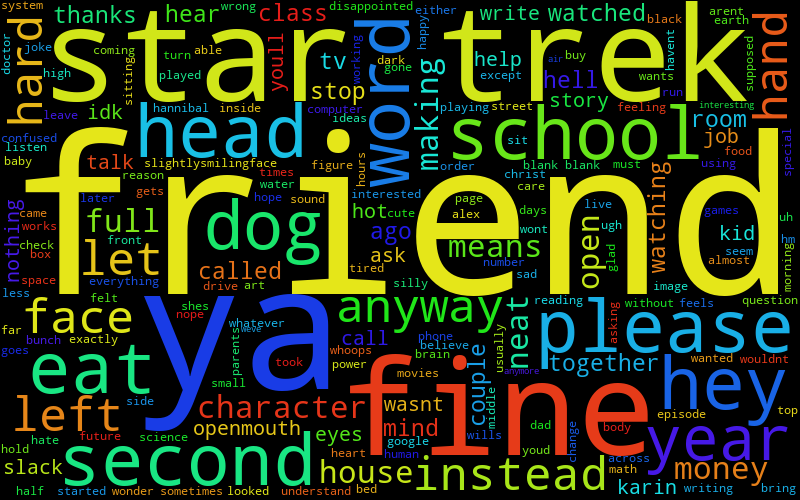
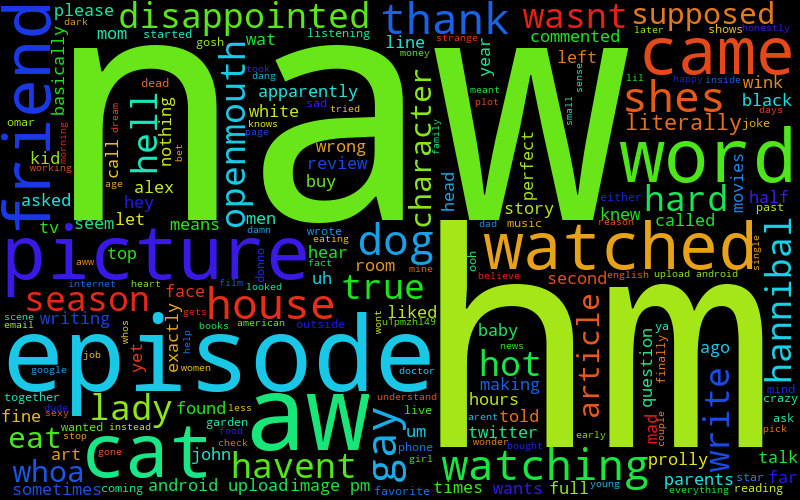
So this works, but it's not super personal with two people, because it's still not removing a bunch of really common words, which will happen when there are more people (then again, if I know anything about Ben, he does love saying the word 'has'). Actually, it doesn't totally work with more people: it's possible for user 3 to check for some word, it gets removed, and then some other word moves up into the top 10 for users 1 and 2, that others don't have, so it won't get checked and removed by them. Luckily, in use, it seems like it's pretty rare that this happens. So what do we get now?
(I've numbered them so that my friends can guess who's who, the keys are at the bottom.)
1
2

3
4
5
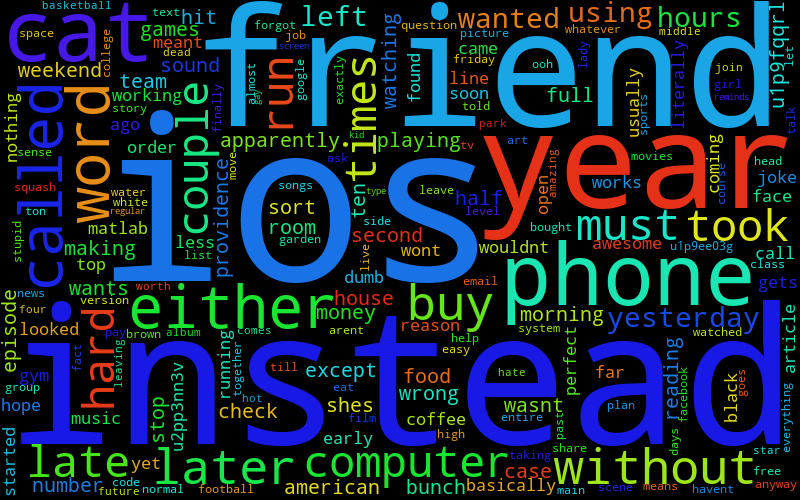
6
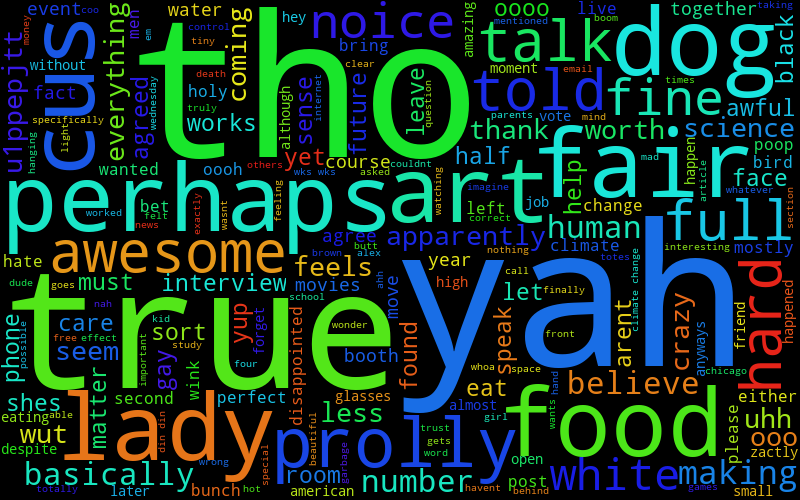
7

8
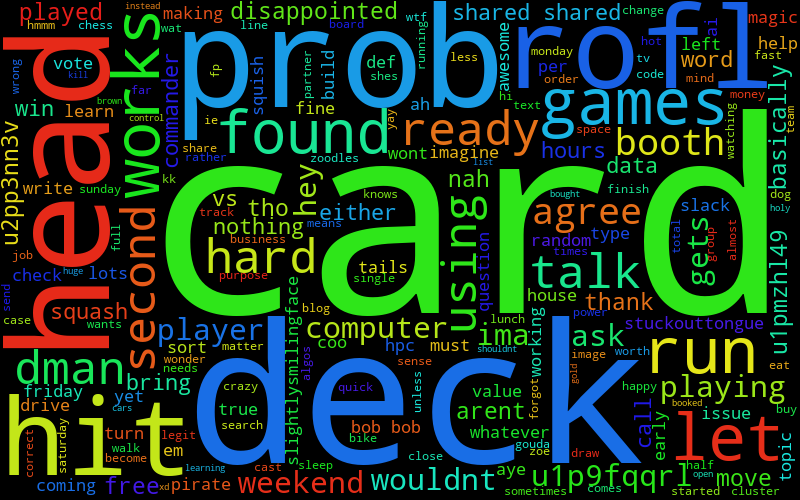
Answers below:
.
.
.
.
.
.
.
- Ben
- Phil
- David
- Liz
- Bobby
- Will
- Declan
- Max
Even if you don't know my friends, you can tell there are pretty strong features. I use a ton of "hmmm", "hahah", and other sentence starter things. Max has a lot of Magic related stuff. Liz has a lot of TV related stuff, since she does that for her job.
However, if you do know my friends, and how they type, I think it's captured it really, really well. After you know people a while, you get really used to little mannerisms and quirks in the way they talk and type, and this has absolutely captured that, like Will's "yah" and "tho" and Ben's "ye" and "whoa" and Max's "dman" and "rofl" and "prob".
When I told my friends about this, it immediately jumped out at them as a Constraint Satisfaction Problem from our Discrete Optimization course. I'm a little disappointed that, having taken the same course, I didn't even think of this when it was so clear to them! After they said it, I see why it could at the very least seem like it's the type of problem that can be solved with it. That said, I thought about it for a little while and can't actually think of how to set the problem up (for a solver like Gurobi, like we used). Also, my friend Max said that this sounds very similar to the problem they have to solve when matching graduating med students to residencies, which is apparently a difficult (open?) problem. This definitely has an additional constraint though, that words can get "eliminated" if they're too common, which I don't think there's an analog for in the med school thing. So maybe I'll think about it more and come back here.
Anyway, that's about all for now. I might go back and do a few more small things someday.